Grigori Fursin created cTuning.org in 2008, established the non-profit cTuning foundation in 2014 and developed the open-source Collective Knowledge technology to help researchers and engineers automate their tedious and repetitive tasks, improve productivity, unleash creativity, accelerate innovation, reduce all R&D costs and make AI accessible to everyone.
"Collective Tuning" is based on Grigori's long and tedious experience pioneering the use of AI and federated learning to automate development of high-performance and cost-effective computer systems, and helping the community reproduce the state-of-the-art research projects and validate them in the real world.
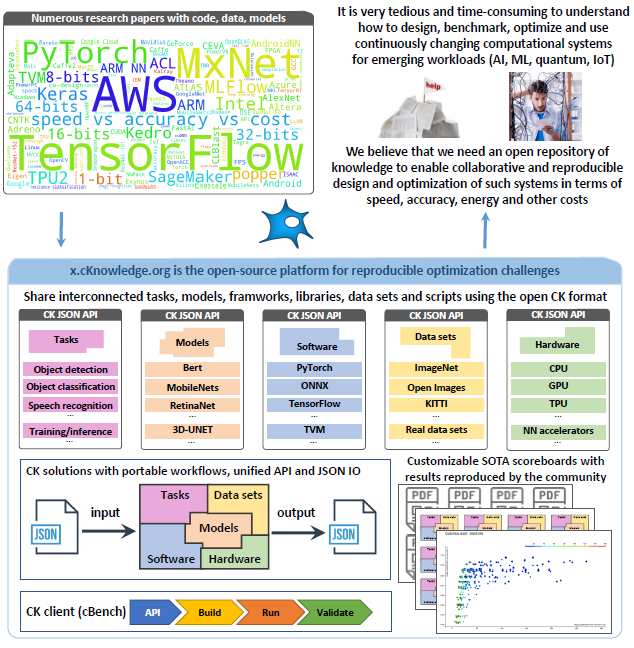
In 2022, we donated our Collective Knowledge v2 to MLCommons and established a public MLCommons task force on automation and reproducibility to continue developing it with the community in an open and transparent way to benefit everyone.
We are now leading the development of a new, open-source, technology-agnostic and portable Collective Mind automation and reproducibility language (CM) to empower everyone from a company expert to a child to automatically reproduce, optimize, integrate and deploy the state-of-the-art AI/ML solutions in the real-world in the fastest and most efficient way while slashing research, development, optimization and operational costs.
CM automation language is adopted and extended by the community via Discord to collaboratively benchmark and optimize AI and ML systems across diverse software, hardware, models and data from different vendors and share all the knowledge and experience via CK playground.
Our open-source technology already helped the community and many companies automate and optimize their MLPerf benchmark submissions while contributing to more than half of all MLPerf inference performance and power results since the beginning.
We also support artifact evaluation and reproducibility challenges at the leading ML and Systems conferences to improve reproducibility, replicability and reusability of research projects in the rapidly evolving world.
We are collaborating with MLCommons and cKnowledge Ltd (our general sponsor) to develop a Collective Knowledge v3 Platform (CK playground) - an open-source platform to empower everyone automatically explore, select, co-design, optimize and deploy the most efficient AI solution based on their requirements and constraints (accuracy, performance, power consumption, size and price) while slashing all development costs and time to market.
The CM automation language and CK playground that we are developing in collaboration with MLCommons are now used to automate reproducibility and optimization challenges for AI/ML systems, MedPerf platform, automotive benchmarking consortium, MLPerf benchmarks, LLM-based assistants and other projects across rapidly evolving software, hardware, models and data.
We are honored that our expertise and open-source technology has helped the following initiatives:
- helped ACM develop a common methodology to reproduce research papers and set up Emerging Interest Group on Reproducibility and Replicbility;
- helped ACM and IEEE conferences organize 20+ reproducibility challanges and artifact evaluations;
- helped MLCommons establish the MLCommons Task Force on Automation and Reproducibility to run MLPerf benchmarks out of the box on any software and hardware from the cloud to the edge using the portable and technology-agnostic Collective Knowledge v3 that we are developing with the community and MLCommons;
- helped students, researchers and practitioners learn the best practices for collaborative and reproducible research: ACM Tech Talk'21 and keynote at ACM REP'23.
Our current community activities include:
- leading the MLCommons task force on automation and reproducibility to automate and simplify the development of Pareto-efficient AI/ML applications and Systems with the help of the Collective Knowledge platform powered by the open-source and technology agnostic automation language;
- organizing optimization and reproducibility challenges and MLPerf submissions with MLCommons to develop high-performance and cost-effective AI/ML applications and systems in terms of speed, accuracy, power consumption, size and costs;
- setting up Artifact Evaluation at AI, ML and Systems conferences to reproduce results from research papers and validate them in the real world across continuously changing models, data, software and hardware;
- unifying the Artifact Appendix and reproducibility checklist across different AI, ML and Systems conferences.
Sponsors
![]()
![]()
![]()